
Java基础
cglib
https://www.runoob.com/w3cnote/cglibcode-generation-library-intro.html
被代理类,没有实现接口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18public class TargetObject {
public String method1(String paramName) {
return paramName;
}
public int method2(int count) {
return count;
}
public int method3(int count) {
return count;
}
public String toString() {
return "TargetObject []"+ getClass();
}
}拦截器,定义一个拦截器。在调用目标方法时,CGLib会回调MethodInterceptor接口方法拦截,来实现你自己的代理逻辑,类似于JDK中的InvocationHandler接口。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18public class TargetInterceptor implements MethodInterceptor{
/**
* 重写方法拦截在方法前和方法后加入业务
* Object obj为目标对象
* Method method为目标方法
* Object[] params 为参数,
* MethodProxy proxy CGlib方法代理对象
*/
public Object intercept(Object obj, Method method, Object[] params,
MethodProxy proxy) throws Throwable {
System.out.println("调用前");
// 调用代理类实例上的proxy方法的父类方法(即实体类TargetObject中对应的方法)
Object result = proxy.invokeSuper(obj, params);
System.out.println("调用后" + result);
return result;
}
}
多线程
Ref
- Monitor
问题
为什么要有多线程?
因为CPU、内存、I/O设备的速度是有极大差异的,为了合理利用 CPU 的高性能,平衡这三者的速度差异,计算机体系结构、操作系统、编译程序都做出了贡献。
在冯诺依曼体系结构(指令存储器和数据存储器合并为一个)下,c = a + b的执行过程。
CPU(Central Processing Unit),算术逻辑单元(Arithmetic Logic Unit),寄存器,控制器(指令寄存器 + PC(Program Counter))
- 这句话经过编译之后,在内存中存在了很多指令和数据
- 指令:load(从内存中的哪个位置load到CPU中的哪个寄存器),add(将CPU的哪两个寄存器中的数据相加,结果放到哪里),store(将存储了结果的寄存器中的数据store到内存中的什么位置)
- 数据:a = 1, b = 2
- CPU中的PC置为第一条指令的位置
- ...
寄存器 -> Cache -> 内存,只能和相邻的设备打交道
为什么有L1 Cache,L2 Cache,L3 Cache?
因为内存太慢了,相比于CPU,所以可以将中间的数据存储到Cache中,比如上面c的值,这样如果需要c的话,直接从Cache中获取,而不是再从内存中load。可见性问题
操作系统创建进程或者线程来实现分时复用。原子性问题
死锁
dump线程查看死锁
避免死锁的方法
- 避免一个线程同时获取多个锁。
- 避免一个线程在锁内同时占用多个资源,尽量保证每个锁只占用一个资源。
- 尝试使用定时锁,使用lock.tryLock(timeout)来替代使用内部锁机制。
- 对于数据库锁,加锁和解锁必须在一个数据库连接里,否则会出现解锁失败的情况。
Synchonized
实现原理
JVM基于进入和退出Monitor对象来实现方法同步和代码块同步,但两者的实现细节不一样。代码块同步是使用monitorenter和monitorexit指令实现的,而方法同步是使用另外一种方式实现的,细节在JVM规范里并没有 详细说明。但是,方法的同步同样可以使用这两个指令来实现。
锁升级
偏向锁
先看mark word中有没有当前线程的id
- 有:当前线程已经获得了锁
- 没有:查看偏向锁标志位
- 是1:CAS将mark word中的threadId修改为当前线程的id
- 是0:CAS锁竞争,也就是轻量级锁
轻量级锁
使用javap -v xxx.class反编译,加锁和释放锁对应的指令为Monitorenter和Monitorexit,依赖于OS的Mutex
Lock实现,Mutex
Lock需要将当前线程挂起并从用户态切换到内核态,这种切换的代价非常昂贵(代价高的原因),所以有了jdk1.6的锁优化。
Object lock = new Object(); 对象头里面有Mark Word表示锁记录,线程执行同步代码块之前会在当前线程的栈帧中创建Lock Record。
如果lock对象没有被锁定的话,锁标志位为01。
- 在Lock Record中分配Mark Word的空间
- 通过CAS操作将Mark Word拷贝到Lock Record中,同时将lock对象的Mark Word中的指针指向该线程的Lock Record,并且锁标记为00
- 如果失败的话,检查Mark Word中的指针知否指向当前线程中的Lock Record,如果是的话说明当前线程已经拿到锁了,并且栈帧中还会有一个新的Lock Record,只不过他存储拷贝的空间是为null。如果不是就说明存在竞争,这样轻量级锁就会失效,直接膨胀为重量级锁。此时lock对象的锁标记为10,同时指针指向重量级锁
出同步代码块时:
- 如果为null说明是重入锁,我猜应该需要一直从栈中取出来
- 如果不为null的话,就通过CAS将Lock
Rock的值恢复给对象头。这里CAS失败的话就说明锁已经升级为了重量级锁,需要走重量级锁的解锁过程,怎么出现这种情况呢?
- 线程A和线程B同时执行,都看到了对象头中的Mark Word中的锁标记为01,A通过CAS拷贝到Lock Record,同时锁标记变成了00,而这时B同过CAS拷贝到Lock Record肯定会失败,因此会膨胀为重量级锁,这样在A释放锁的时候通过CAS操作将Lock Record的值恢复给对象头就会失败
锁膨胀的过程:
上面提到了当一个线程拿到锁之后,另一个线程再想通过CAS将对象头的Mark Word拷贝到栈帧中的Lock Record的话就会失败。
- 为lock对象申请Monitor锁,让lock指向重量级锁的地址
- 自己进入到Monitor的EntryList中,这个时候Monitor的Owner为线程A,即之前通过轻量级锁的方式拿到锁的线程。
- 当线程A执行完同步代码块中的内容后,执行轻量级的解锁过程,即通过CAS的方式,将Mark Word的值拷贝给lock对象,这时候会失败,之后走重量级锁的解锁过程(这个上面也说到了)
- 将Monitor的Owner置为null,唤醒EntryList中BLOCKED的线程(这里是非公平的),Monitor中还有WaitSet,这里面存的是之前获得过锁,但是条件不满足进入到WAITING的状态
进入到WaitSet的过程:
Owner线程发现某个条件不满足,然后调用lock.wait()等待其他线程唤醒自己,此时当前线程就会进入到WaitSet中,状态为WAITING。WAITING和BLOCKED都是处于阻塞的状态,不占用CPU,BLOCKED状态的线程会在Owner线程释放锁的时候唤醒竞争锁,而WAITING状态的线程需要等到其他线程调用notify或者notifyAll来唤醒,并进入到EntryList中竞争锁。
volatile
ref
- cpu缓存和volatile - XuMinzhe - 博客园 (cnblogs.com)
- 就是要你懂Java中volatile关键字实现原理 - 五月的仓颉 - 博客园 (cnblogs.com)
- CPU多级缓存 | 闪烁之狐 (blinkfox.github.io)
- 关键字: volatile详解 | Java 全栈知识体系 (pdai.tech)
- bcst_csapp/mesi.c at main · yangminz/bcst_csapp (github.com)
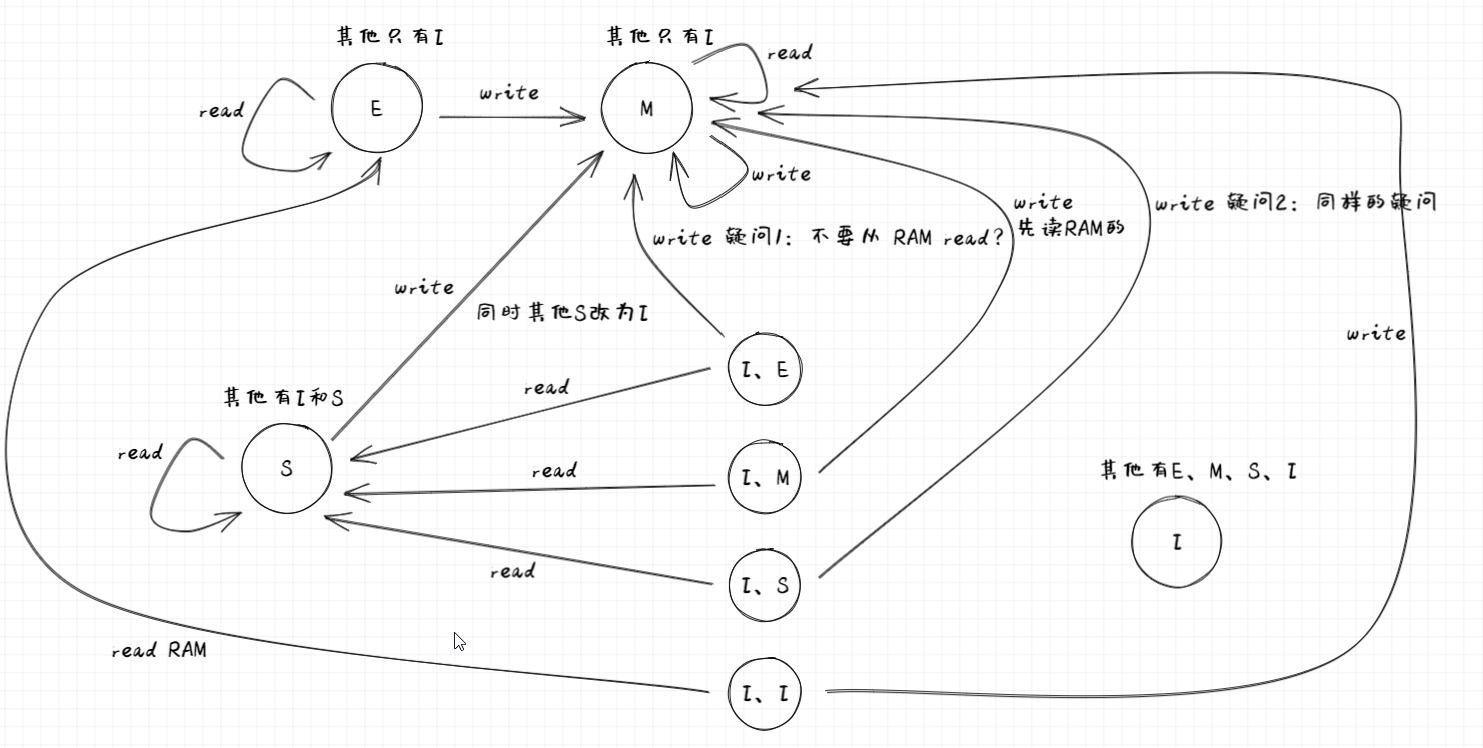
MESI协议
状态转换
read:
- E --> read cache (read hit)
- M --> read cache (read hit)
- S --> read cache (read hit)
- I --> (read miss)
- 有 M,将 M 的 value 写到 RAM,从 RAM 中读取,同时 M --> S 且 I --> S,return
- 有 E,从 E 的 value 中读取,同时 E --> S 且 I --> S,return
- 有 S,从 S 的 value 中读取,同时 I --> S,return
- 其他也都为 I,从 RAM 中读取,I --> E
write:
- E,直接 write,同时 E --> M
- M,直接 write
- S,其他的都改为 I,write,S --> M
- I
- 有 M
- M 的 value 写到 RAM
- M --> I
- RAM --> 当前
- 当前修改
- I --> M
- 有 E
- E --> I
- 当前修改
- I --> M
- 有 S
- 将所有其他的都 --> I
- 当前修改
- S --> M
- 其他都为 I
- RAM --> 当前
- 当前修改
- I --> M
- 有 M
JVM做的事情
当遇到对于volatile变量的写时,JVM会在对应的汇编指令上添加Lock,Lock的作用为:
- 写回内存
- 广播无效
以前的处理器都是锁BUS,但是这样其他修改也会被阻塞住(还有开销大?),所以后来都采用锁cache line的做法,为了保证缓存的一致性,又有了EMSI协议。