
redis之IO多路复用
2023-03-25 15:34:50
本文总阅读量次
问题
- 为什么需要IO多路复用?
前置知识
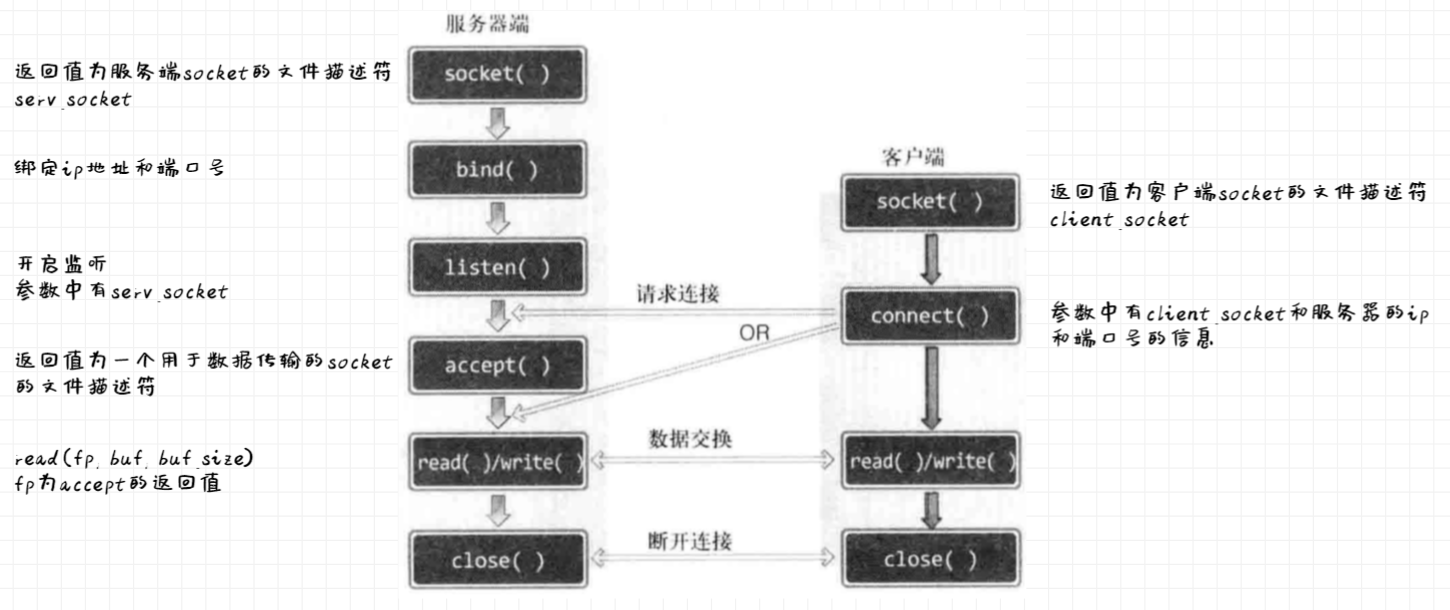
select
过程
- 设置需要监控的文件描述符
- 这里使用fd_set结构体,使用一堆的宏来定义的,最终的结果为:
sizeof (long int)为4or8,如果为4的话,每一个数能表示32位,32*32=1024,所以很多地方写的1024就是这么来的。 初始化监控的文件描述符就是将对应位置的位改为1,linux提供了很多的api来修改fd_set的值。
1
2
3typedef struct{
long int fds_bits[32];
} fd_set;
- 这里使用fd_set结构体,使用一堆的宏来定义的,最终的结果为:
- 调用select函数
- 函数声明为: 以readset为例,关于这里的监听read系统调用的fd的意思,我的理解是:以服务端为例:
1
2
3
4
5
6
7int select(
int maxfd, // 一般为最大的fd+1
fd_set *readset, // 监听read系统调用的fd
fd_set *writeset, // 监听write系统调用的fd
fd_set *exceptset,
const struct timecval *timeout // 超时时间,0不等待,-1一直等待,其他值
);- 对于socket()返回的用于监听的fd,他需要监听是否有连接的请求,也是read系统调用。
- 当建立完连接后(这里又创建了一个新的socket用于数据传输)需要等待客户端发来的信息,在客户端还没有写数据前这个新的socket会一直阻塞住,为了不阻塞,我们需要一直监听read系统调用的fd是否就绪。
- 函数声明为:
- select函数调用完成后,对应位为1的fd表示已经准备好,因此在循环调用select时,需要每一次初始化好需要监控的fd。
代码 《TCP/IP网络编程》 P203
- 28行:最一开始select中监听的fd只有这个serv_socket
- 58行:假设一共有5和客户端与该server连接,那么这里就会执行5次,最终监听的fd就有五个,一个是用于监听客户端连接的fd,另外五个是监听客户端什么时候写数据,在服务端就是read系统调用
- 49行:在调用select,内部判断fd是否就绪时,需要从用户态切换到内核态:
- 将fd_set拷贝到内核空间
- 内核遍历fd_set查看哪些fd已经准备就绪,如果已经就绪,在该位置就会打上一个标记(设为1),遍历完后返回已经就绪的个数,用户态发现准备就绪的fd的个数大于1,就从头遍历一遍找到就绪的fd,执行相应的操作(在这里就是read系统调用)。有一种情况就是在内核态中遍历一遍后发现没有一个fd是准备就绪的,那么这里又有两种策略:
- 一直循环检查,会一直占用CPU
- 遍历一遍之后将该进程阻塞住,当客户端给服务端发送数据时,数据会通过网络传输到达网卡,网卡会通过DMA的方式将这个数据写到指定的内存当中,写入完成后会通过中断信号告诉CPU有了新的数据包到达,CPU收到中断信号后会进行响应中断,并调用中断的处理程序进行处理,根据这个数据包的ip和端口号找到这个socket,将数据写到这个socket的buffer中,再检查这个socket的等待队列当中是否有进程进行阻塞等待,如果有的话就唤醒该进程,接下来就是和之前一样的操作了。
poll
1 | int poll(struct pollfd *fds, nfds_t nfds, int timeout); |
poll相比于select有了两个优化:
- 不需要每次重置需要监听的fd,因为用了新数据结构,fd包含了需要监听的fd
- 将fds拷贝到内核态时,底层使用的是链表,所以没有了1024的限制
问题
- 每次还是需要用户态到内核态的切换,并将所有的fd拷贝到内核态中
- 并不知道哪些fd是准备就绪的,所以需要遍历所有的fd
epoll
1 | int epoll_create(int size); // 返回值为创建的epoll的文件描述符 |
ref
- https://blog.csdn.net/Zorro721/article/details/107565000
- https://www.bilibili.com/video/BV1r54y1f7bU/
- https://man7.org/